Today we will focus on the practice of importing data - better than last time.
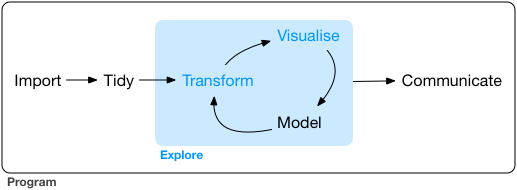
Our framework for the workflow of data visualization is shown in Figure 25.1
Figure 12.1: Tidyverse framework again
Acquiring and importing data is the most complicated part of this course and data visualization in general. This Unit is done now, rather than at the beginning, because of its difficulty and pain - while providing little immediate satisfaction of a cool map or graphic. In my experience, data import and manipulation is 80+% of the work when creating visualizations; it needs to be covered at least nominally in any course on data visualization.
12.1 Load and Install Packages
As always, we should load the packages we need to import the data. There are many specialized data import packages, but tidyverse and sf are a good start and can handle many standard tables and geospatial data files. Remember, you can check to make sure a package is loaded in your R session by checking on the files, plots, and packages panel, clicking on the Packages tab, and scrolling down to tidyverse and sf to make sure they are checked.
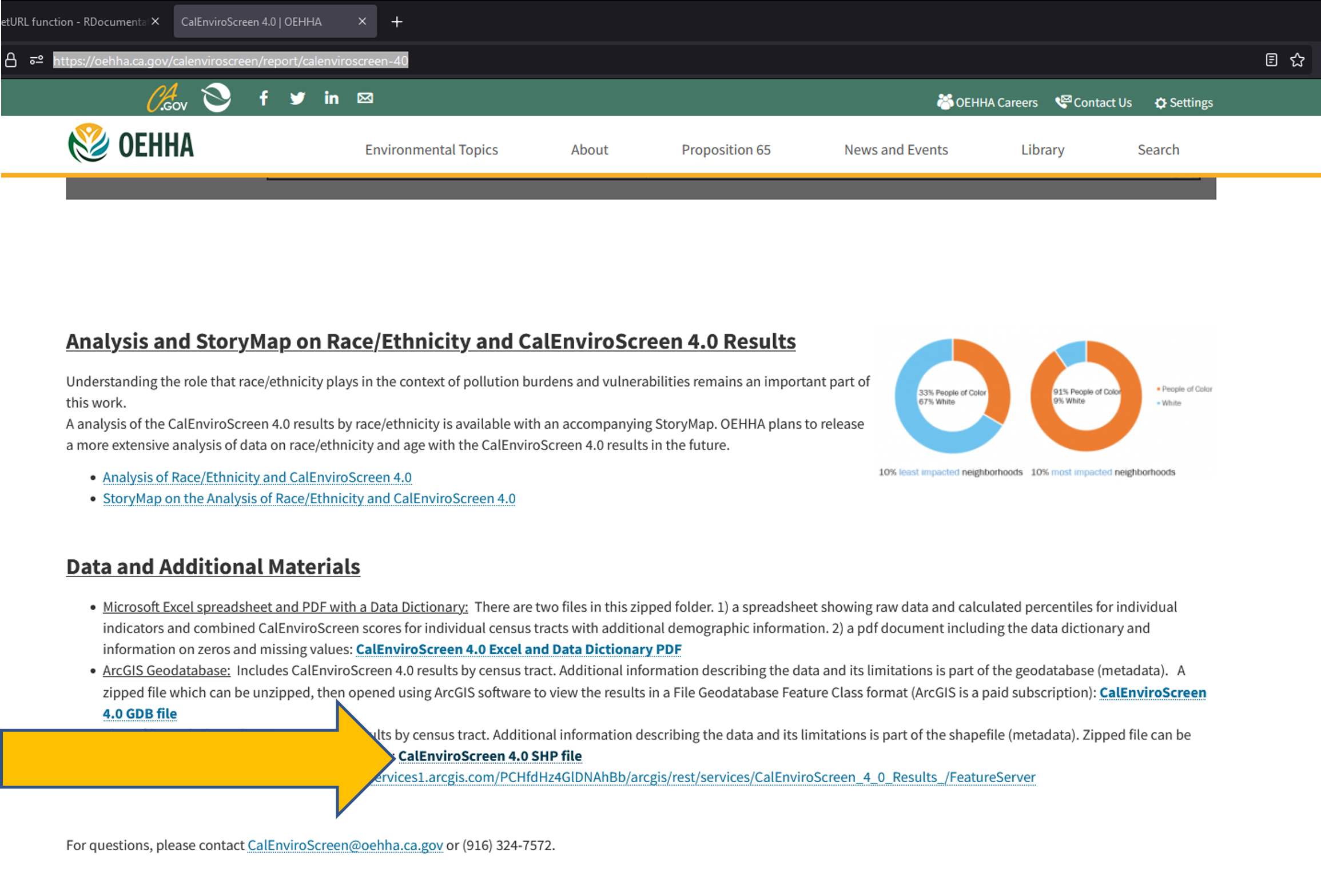
Download the Zipped Shapefile shown in the screenshot in Figure 12.2
Figure 12.2: CalEnviroScreen Shapefile Location
By default, downloads are often placed in a Downloads directory, although you may have changed that on your local machine.
You can skip the next step if you directly save the zip file to your working directory.
12.2.2 Move the Zipped Shapefile to the R Working Directory
By default, downloads are often placed in a Downloads directory, although you may have changed that on your local machine. If this occurred in your download, the zipped needs to be either (a) moved to the R working directory or (b) identify the filepath of the default download directory and work with it from there.
For today, I will only show path (a) because it is good data science practice to keep the data in a directory associated with the visualization.
Identify the directory where the zipped shapefile was downloaded. On my machine, this is a Downloads folder which can be accessed through my web browser after the file download is complete. The name of the file is calenviroscreen40shpf2021shp.zip.
Identify the R working directory on your machine using the getwd() function.
Move calenviroscreen40shpf2021shp.zip from the default download directory to the R working directory. Either drag it, copy and paste it, or cut and paste it. For Macs - use the Finder tool. Here’s a youTube video on how to move a file - start at 0:27 seconds.
On a PC, right-clicking on a zipped file will bring up a menu that includes an Extract All option. Choosing the Extract All option brings up a pathname to extract the file to. The default is to extract the zip file to a subfolder named after the zip file.
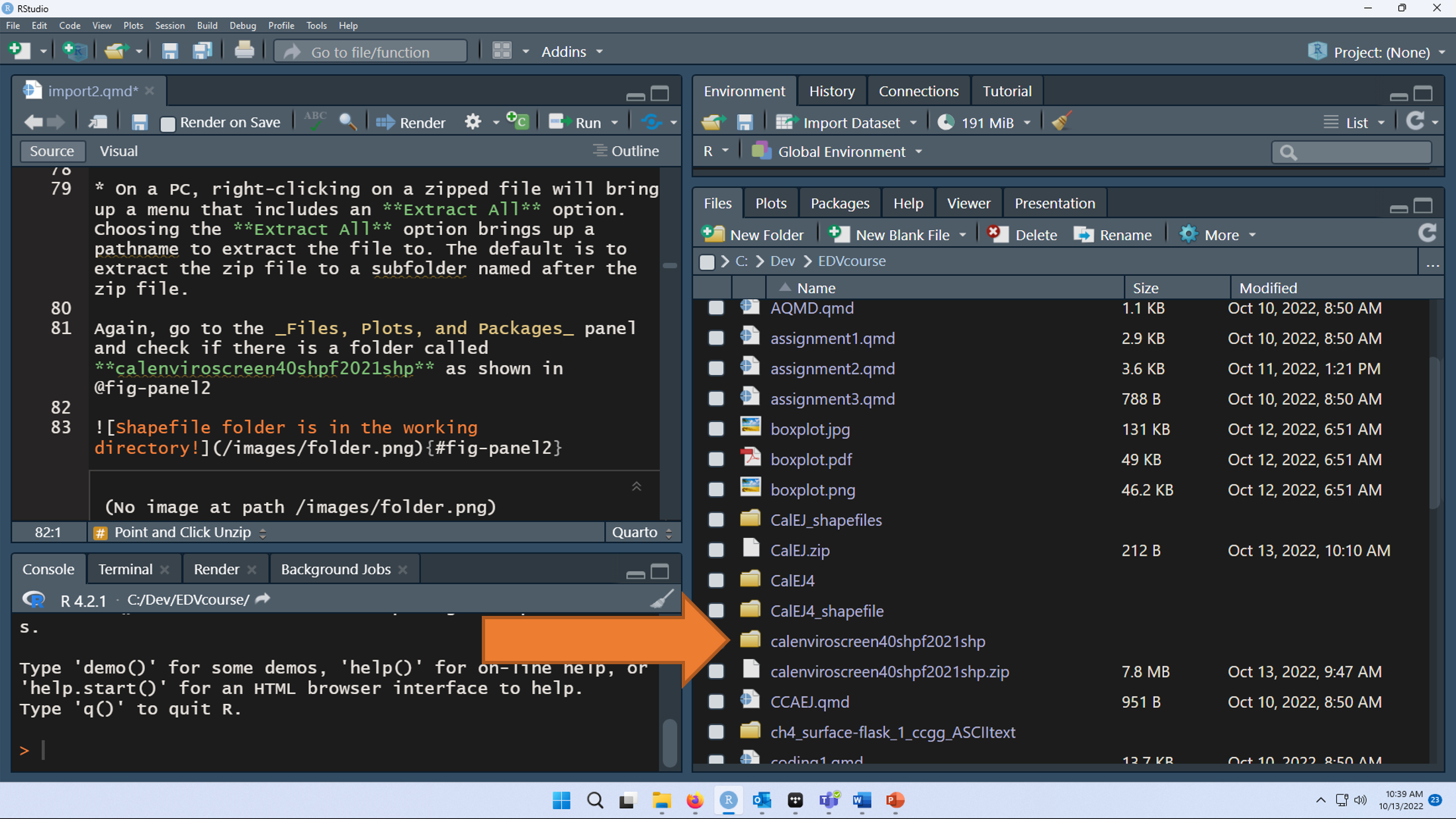
Again, go to the Files, Plots, and Packages panel and check if there is a folder called calenviroscreen40shpf2021shp as shown in Figure 12.4.
Figure 12.4: Shapefile folder
The sf library is used to import geospatial data. As before, st_read() is function used to import geospatial files.
Shapefiles are the esri propietary geospatial format and are very common.
The CalEnviroScreen data are in the shapefile format, which is a bunch of individual files organized in a folder directory. In the calenviroscreen40shpf2021shp directory, there are 8 individual files with 8 different file extensions. We can ignore that and just point read_sf() at the directory and it will do the rest. The dsn = argument stands for data source name which can be a directory, file, or a database.
Reading layer `CES4 Final Shapefile' from data source
`C:\Dev\EA078_Fall2024\calenviroscreen40shpf2021shp' using driver `ESRI Shapefile'
Simple feature collection with 8035 features and 66 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -373976.1 ymin: -604512.6 xmax: 539719.6 ymax: 450022.5
Projected CRS: NAD83 / California Albers
Check the Environment panel after running this line of code. Is there a CalEJ file with 8035 observations of 67 variables present?
If so, success is yours! Let’s make a map of Pesticide census tract percentiles to celebrate with Figure 12.5!
12.2.4 Visualize the data
The whole California map is too big, so I am just going to show the southernmost counties here by using the filter function for a small subset of counties. We’ll also remove the tracts with no pesticide information (-999).
We did this before for Alert, let’s try the successful code using the read_table() function. Note, that when I follow the link, the first line of the dataset says there are 71 header lines.
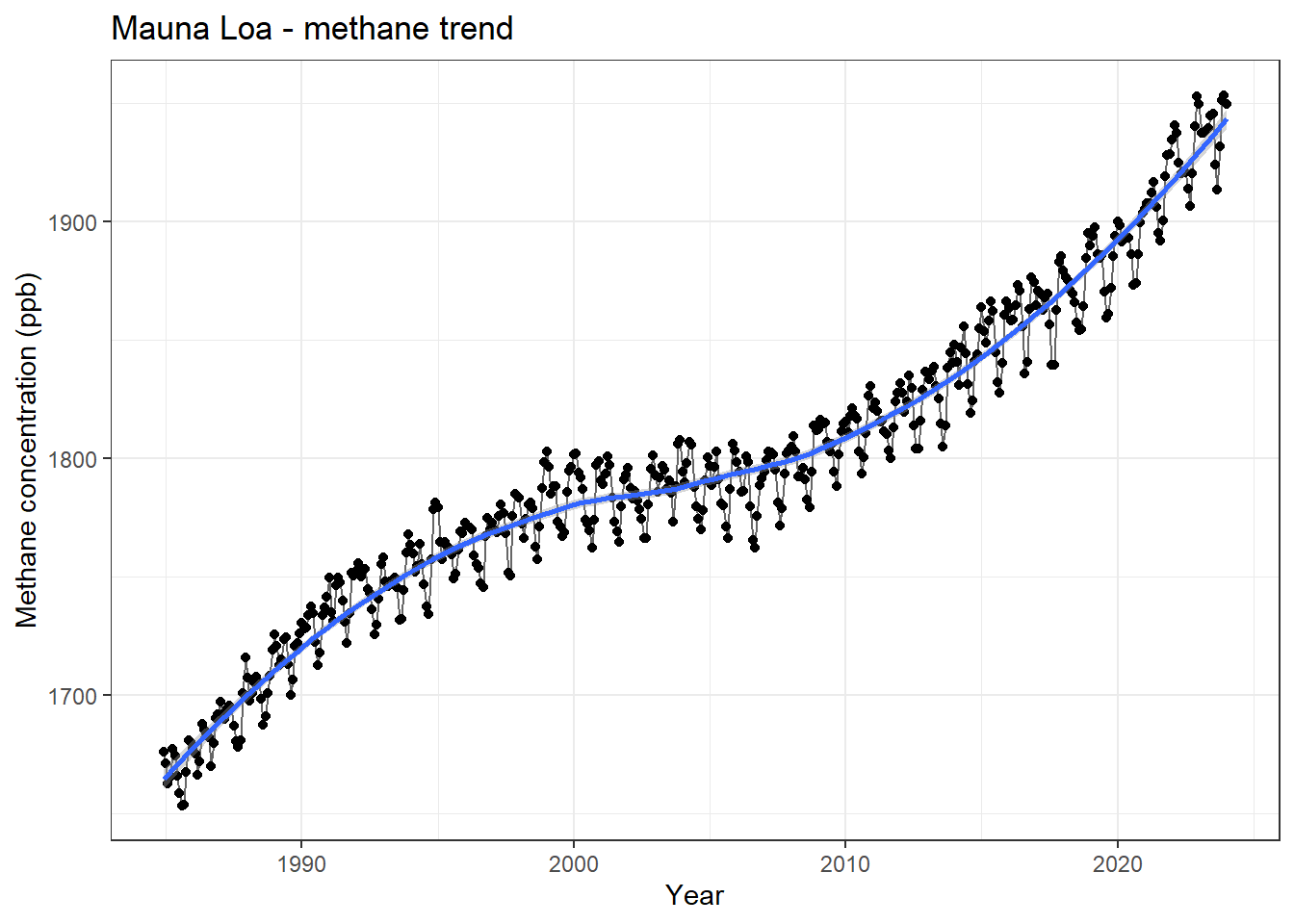
MLO.CH4|>mutate(decimal.Date =(year+month/12))|>ggplot(aes(x =decimal.Date, y =value))+geom_point()+geom_line(alpha =0.6)+geom_smooth()+theme_bw()+labs(x ='Year', y ='Methane concentration (ppb)', title ='Mauna Loa - methane trend')
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
Figure 12.6: Trend in Methane concentrations (ppb) at Mauna Loa, Hawaii
12.2.6 Advanced data visualization
Now that we have Mauna Loa, I want to add the Alert dataset to it using the code we developed last week. This code downloads the Alert dataset and renames its headers.
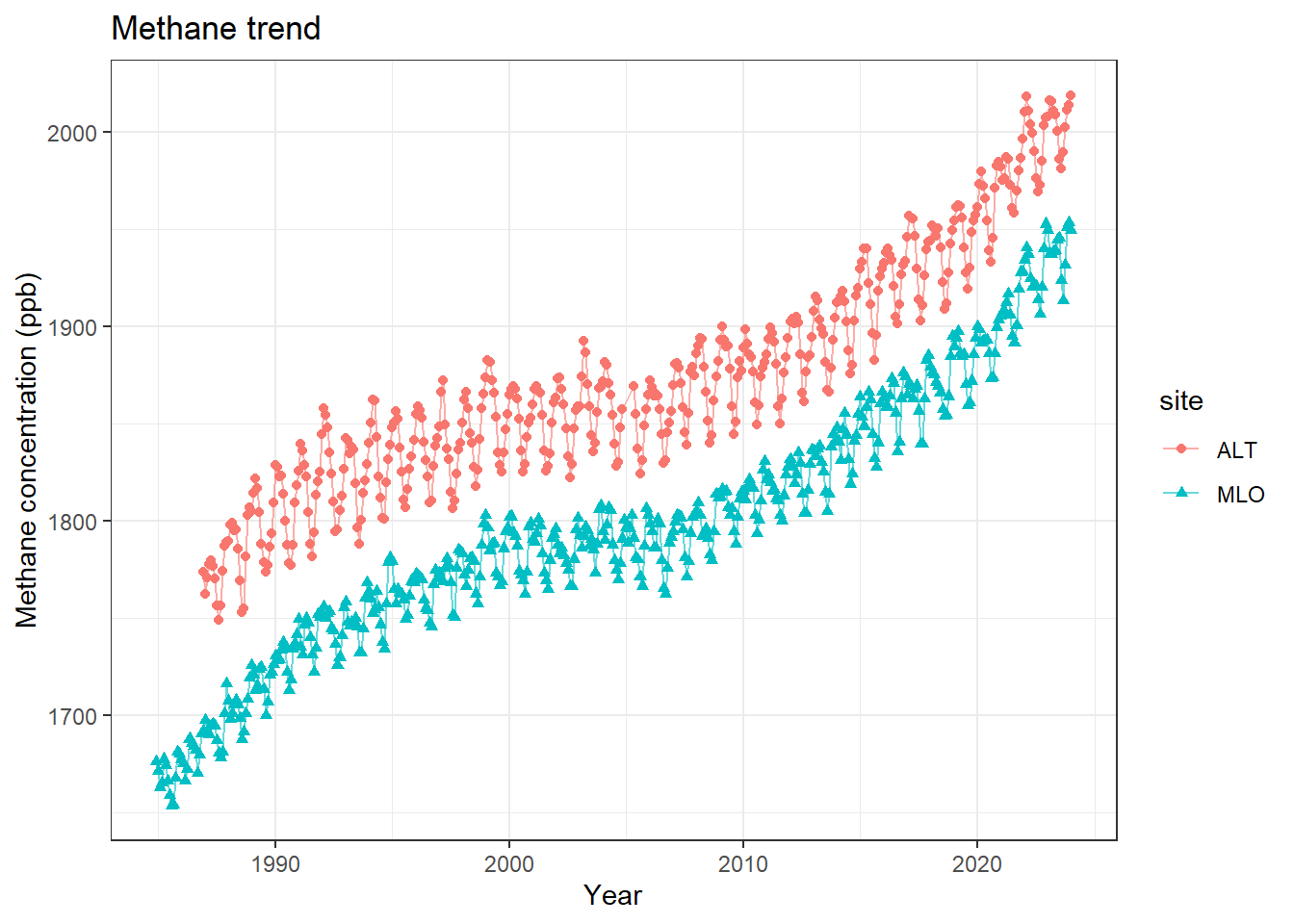
Now we can put the datasets together to make a combined visualization. The bind_rows() function from tidyverse let’s us put the datasets take together since they have the same headers. Then we can use the color argument to aes() to get two separate time series as shown in Figure 12.7. I also grouped the data by the shape of the symbol to ensure that the two datasets are distinguishable.
CH4<-bind_rows(ALT.CH4, MLO.CH4)CH4|>mutate(decimal.Date =(year+month/12))|>ggplot(aes(x =decimal.Date, y =value, color =site, shape =site))+geom_point()+geom_line(alpha =0.6)+#geom_smooth(se = FALSE) +theme_bw()+labs(x ='Year', y ='Methane concentration (ppb)', title ='Methane trend')
Figure 12.7: Trend in Methane concentrations (ppb) at Mauna Loa, Hawaii and Alert, Canada
12.2.7 Downloading secured zip files
I have not yet found a reliable method to get this to work every time on Macs and PCs. Stay tuned.
A file named Environmental Justice Index 2022 result.geojson should appear in your default download folder.
Move the Environmental Justice Index 2022 result.geojson file to the working directory.
Check the Files panel. Is Environmental Justice Index 2022 result.geojson there?
Read in the file using read_sf(). The dsn argument can point directly to the file name for this type of file. Assign it a name that incorporates EJI and the state abbreviation.
Check the Environment panel. Did it import?
Make a visualization - but not a map because projections are wonky?
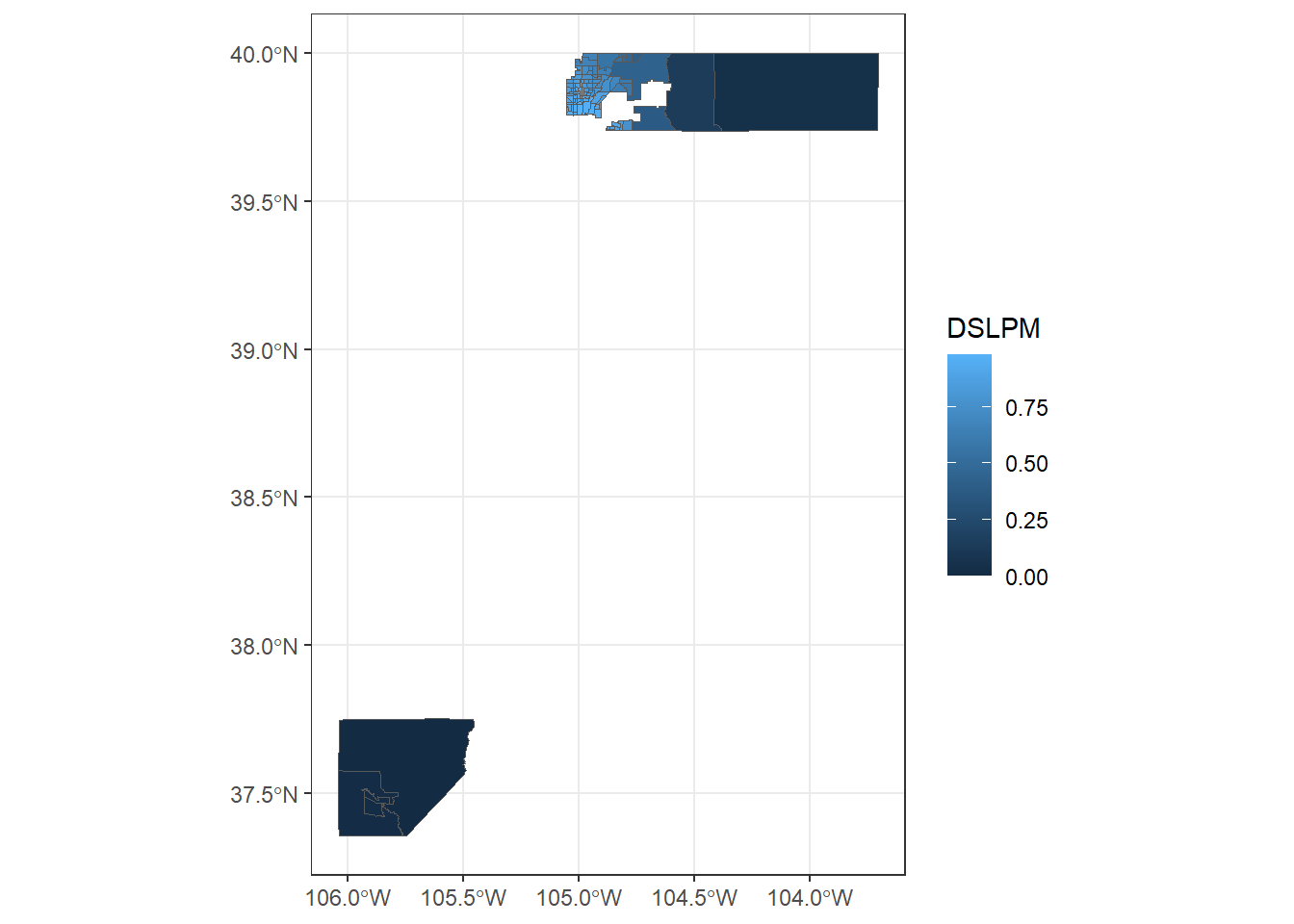
CO_EJI_raw<-sf::st_read(dsn ='Environmental Justice Index 2022 result.geojson')|>sf::st_transform(crs =4326)|>mutate(DSLPM =as.numeric(EPL_DSLPM))# for some reason all the values are importing as character values
Reading layer `Environmental Justice Index 2022 result' from data source
`C:\Dev\EA078_Fall2024\Environmental Justice Index 2022 result.geojson'
using driver `GeoJSON'
Simple feature collection with 100 features and 119 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: -106.0394 ymin: 37.35623 xmax: -103.7057 ymax: 40.00146
Geodetic CRS: WGS 84
# this code converts one row to numeric
Figure 12.9 shows Diesel PM from their environmental indicators layer for San Bernardino County.